Now also available via Tor
http://iwccx6ebuapto7dlkd4m5fooud6nqn2z7go7aass5c4q6vl6gzs5htad.onion/
Einträge
-
Verilog: How does a CPU actually work?
Verilog series
A.k.a. “What’s a fetch-decode-execute” cycle?
So, yeah, I studied electrical engineering, and I learned about the usual CPU execution cycle, and the CPU architectures von Neumann vs. Harvard, but I never really thought much about it, it was always very abstract.
Now, with my Verilog experiments, I could dig deeper into this. I implemented both the Nandgame CPU and Ben Eaters 8 bit breadboard CPU1.
The Nandgame one was easy, as fetch/decode/execute would happen basically within one cycle. (Harvard2 architecture).
However, with the Ben Eater CPU (von-Neumann) architecture, things get a bit more involved. In his video series, Ben used an EEPROM to manage the execution. But I thought I can do better! With a Finite State Machine! The states usually go like
PC_to_MAR <-----\ Get contents of program counter, | | move to memory address register. | | v | MEM_to_INS_PC_inc | memory contents to instruction register, | | increment program counter, | | determine next state based on instruction. v | .. instruction .. | usually executes the actual instruction. .. dependent .. | might take multiple cycles. | | +------------/ | | (eventually) v HALT <+ Nothing is done anymore. +----+It took me some time to figure out how to do it exactly, especially since I still had to figure out how clocked vs combinatoric components work. One of the tricks “to make it more efficient” was to negate the PC clock, this way, I could increment the program counter basically in the same clock cycle as the instruction was decoded (step 2 of the state machine), only on the falling edge.
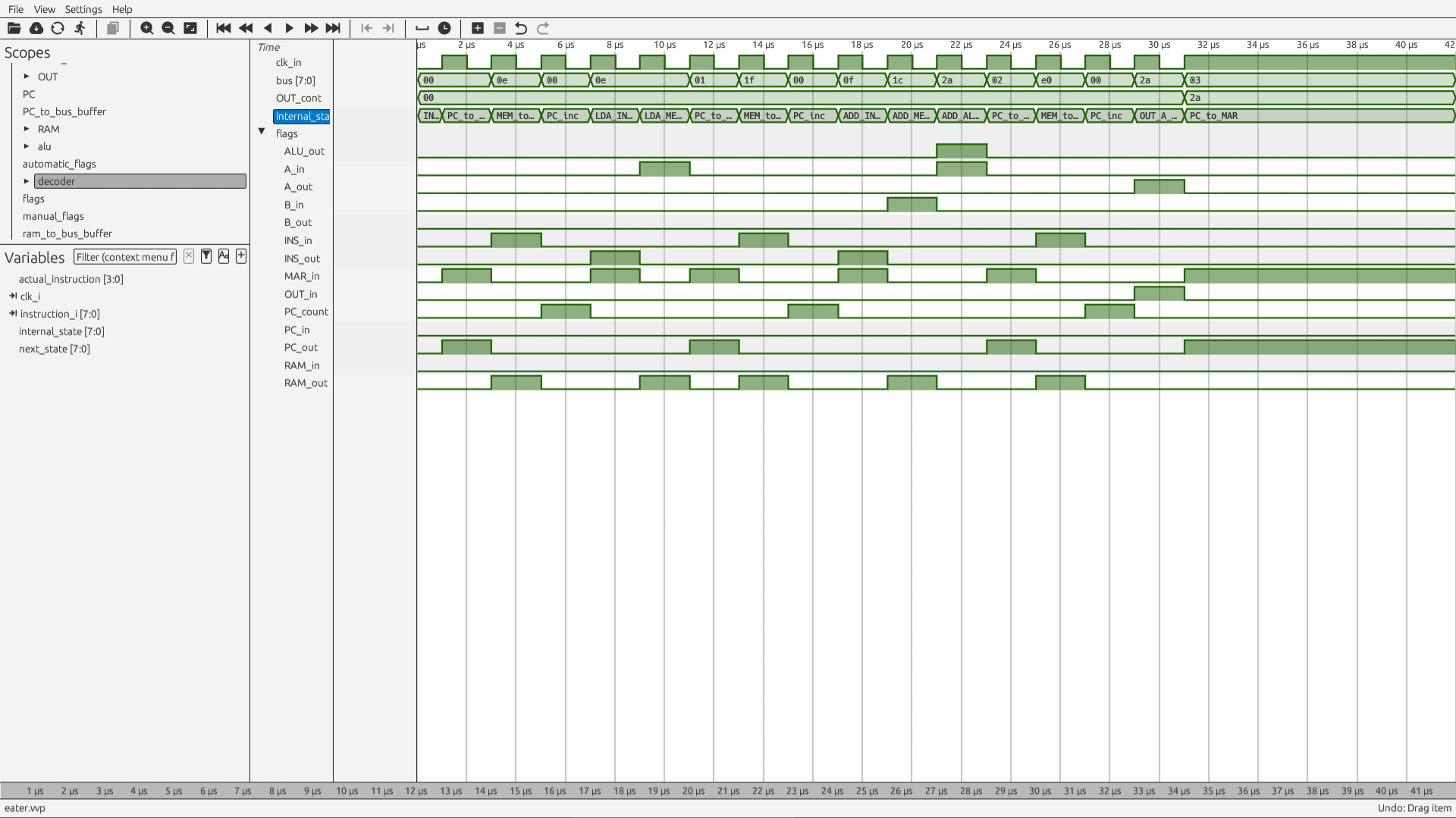
What’s nice, I can simulate this and record the waveforms, to get an even better understanding of what exactly happens:
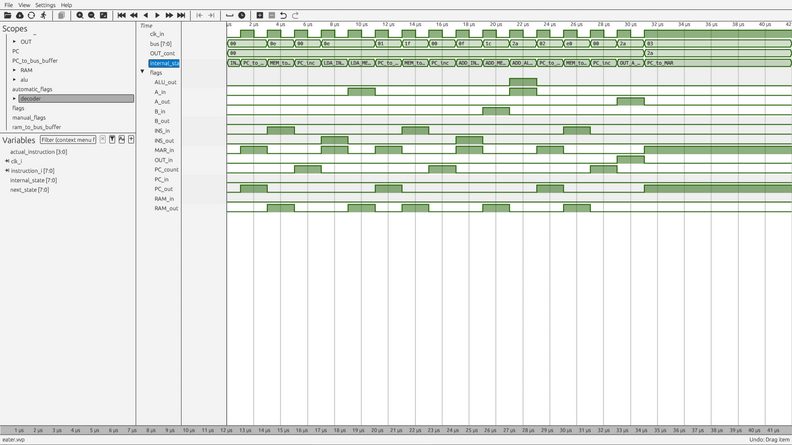
Unfortunately, I couldn’t both get the “full state names” into the picture, as well is the whole program. My screen width is limited. I put the whole stuff on my git repo, though, so feel free to check it out.
Footnotes
-
Using Passkeys under GrapheneOS with KeePassDX
How to properly enable Passkey usage under GrapheneOS with KeePassDX -
Updating my servers to Trixie
Reports on upgrading Debians servers. What went well. What went wrong. -
Getting started with Verilog
First experiments with Verilog, mostly simuluated. -
FPGA development board
Showing off my FPGA dev board. -
GLC 2025 Con report
How the GLC 2025 went for me. -
Packing Worries
A con is coming up. What should I pack? -
Gadgetbridge won't sync my calendar events to my Pebble
Working around non-working event sync. -
Installing CA certificates on Android (also 16)
Installing CA certificates on Android.